So it’s rare that I have an outage in my home infrastructure that turns into a perfect storm, but this was an interesting edge-case I had never thought of — and one worth talking about.
Background - infrastructure and services#
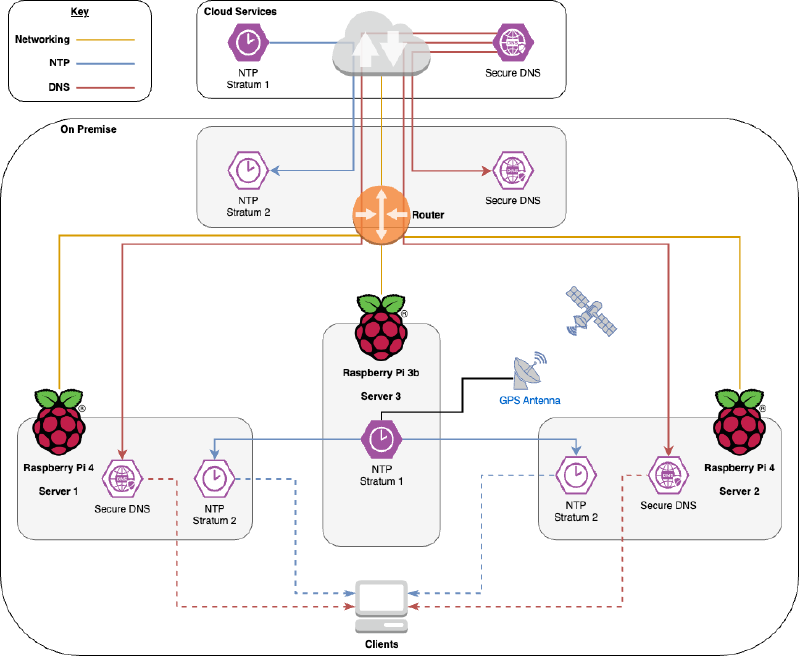
In my home infrastructure I run a pair of servers that provide DNS and NTP services to my network. These are both Raspberry Pi 4 SBCs (Single Board Computers), which we’ll refer to as Server 1 and Server 2. I also have a Raspberry Pi 3B+ SBC with a GPS hat, which serves as my dedicated Stratum 1 time server. We’ll call this Server 3.
DNS#
Server 1 and Server 2 provide DNS to my network, with DoT (DNS over TLS) and DoH (DNS over HTTPS) as upstream sources. This ensures all external DNS traffic is encrypted in transit and not visible to the ISP.
Downstream, these servers provide DoT, DoH, as well as regular DNS service. Since DoT and DoH require certificates, both servers use regularly renewing Let’s Encrypt certificates — trusted by internal clients without needing to distribute an internal certificate chain.
This certificate requirement and configuration will become important later.
NTP#
Server 3 (the Raspberry Pi 3B+ with GPS hat) provides accurate GPS time (and no, not the position of my house in case I lose it — I’m not that stupid). This time source is distributed across the network using Chrony, giving me a Stratum 1 time server.
Both Server 1 and Server 2 run Chrony, pointing to Server 3. This makes them Stratum 2 time servers, which all other clients can use to keep accurate clocks.
Network#
One other detail: the router (a Ubiquiti model) is configured with the same upstream DNS as Server 1 and Server 2. For NTP, it uses a cloud-based Stratum 1 server in Canada, Torix. This detail also matters later.
The incident#
In January, a power outage lasted longer than four hours, which of course shut down the entire infrastructure. Nothing too serious — these things happen. I received a notification from Ubiquiti that the router had gone offline. No problem: no power, no internet.
But when power was restored, services didn’t come back online as expected.
Symptoms#
The first indication that something was wrong was that clients couldn’t resolve anything via DNS. Strangely, the Ubiquiti kit reported that internet access had been restored. A quick check of the control panel confirmed this was true.
Testing from the clients showed outbound connectivity worked fine (direct IP connections succeeded), so the issue pointed to the DNS servers.
Troubleshooting was harder because both DNS servers are headless. Stranger still, I couldn’t SSH into them using their internal DNS names. That meant internal DNS was broken too. After SSHing directly via IP, I confirmed that DNS services on both Server 1 and Server 2 had failed to start — because the certificates were “invalid.”
At first, I assumed the power outage had coincided exactly with certificate expiry, but that shouldn’t have mattered since Let’s Encrypt renews a month ahead. This made me question whether my renewal code was working correctly.
But when I inspected the certificates, they were still valid. Stranger and stranger. Running OpenSSL validation finally revealed the clue: the certificates were “not yet valid.”
The smoking gun!
A quick timedatectl later confirmed that Server 1 and Server 2 thought they were years in the past.
The cause#
A bit of background. SBC’s like the Raspberry Pi series (before series 5) do not have internal clocks (nor onboard batteries). This means that when they first boot they connect to the internet to retrieve the time and set their RTC (Real Time Clock). Something had happened to cause Server 1 and Server 2 to fail setting their RTC.
The culprit? A boot failure on Server 3, which prevented its NTP service from coming up. Since I had (foolishly) configured Servers 1 and 2 to use only Server 3 for NTP, they had no alternative internal or external time sources. Worse, their DNS configs pointed to themselves as upstream, so they couldn’t even resolve an external NTP server if they wanted to.
As a result, the servers reset their clocks back to epoch time, which made the Let’s Encrypt certificates look “not yet valid.”
The fix#
This part is boring. Server 3 hadn’t really failed, it had just hung during boot, and was fixed by a simple power cycle. After that, rebooting Servers 1 and 2 allowed them to sync their RTC and resume service.
Looking forward#
The outage turned out to be more about design than disaster. I had built my setup so that everything depended on one GPS-powered time server. When that failed to start, the whole chain fell apart.
The fix is straightforward:
- Give my DNS servers a backup time source on the internet, so they aren’t stranded if the GPS server is down.
- Let the GPS time server itself also fall back to cloud-based time, just in case.
This way, the local GPS-based time remains the preferred source (fast and accurate), but there’s always a safety net.
For DNS, I’m keeping things self-contained to avoid any chance of my traffic falling back to insecure, plaintext lookups — but that’s a trade-off I accept for privacy.
In short: redundancy matters, even in a small home lab. One missing link in the chain can ripple out in surprising ways.
Fixing NTP#
Server 1 and Server 2 should have an alternative time source in their Chrony configs. This doesn’t mean they’ll use it unless needed. With internal latency <100 ms and Torix latency >3000 ms, the local Stratum 1 will always be preferred when available.
Note: Identifiable information (internal IPs, secrets) has been obfuscated.
server 192.168.1.13 iburst key 01 prefer
pool ntp.torix.ca iburst$ chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 192.168.1.13 1 9 377 440 +7478ns[ +10us] +/- 287us
^? ntp3.torix.ca 1 10 173 473 -5769us[-5766us] +/- 49ms
^? ntp2.torix.ca 1 10 253 37 -3955us[-3955us] +/- 48ms
^? ntp1.torix.ca 1 10 333 393 -3458us[-3458us] +/- 47msServer 3 is also now configured with Torix as a backup upstream, using a split configuration:
refclock PPS /dev/pps0 lock NMEA trust prefer
refclock SHM 0 refid NMEA trust noselect
#Backup TORIX pool
pool ntp.torix.ca iburst
# Backup TORIX pool without requiring DNS
server 206.108.0.131 iburst
server 206.108.0.132 iburst
server 206.108.0.133 iburstThis gives us the following result:
$ chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
#* PPS0 0 4 7 12 +73ns[+4188us] +/- 249ns
#? NMEA 0 4 7 11 +92ms[ +92ms] +/- 252us
^? ntp1.torix.ca 1 6 17 43 -3661us[ -557us] +/- 47ms
^? ntp2.torix.ca 1 6 17 43 -3786us[ +402us] +/- 48ms
^? ntp3.torix.ca 1 6 17 43 -4167us[-1063us] +/- 48msFixing DNS#
There’s no great way to fix this. If DNS on Server 1 and Server 2 goes offline, I don’t want queries falling back to plaintext. For now, I’ve opted to keep them self-reliant for DNS.
Legal#
In accordance with My AI Policy, AI was used to proof-read the article for spelling, grammar and sentence structure prior to publishing.
The events detailed within this document are real and occurred in January of 2025. While some detail and technical fact-finding has been glossed over, the key points and facts are accurate.
